The Internet Is On Fire Today Why So Many Major Services Are Down at the Same Time
If you tried to do basically anything online today, you probably ran into a wall of 500 errors. And it wasn’t just you — a surprising cluster of major platforms all went down within minutes of each other. GitLab? Down. Cloudflare? Down. Claude.ai? Down. Shopify stores? Also down. Even LinkedIn started throwing 500s like it’s 2012 again.
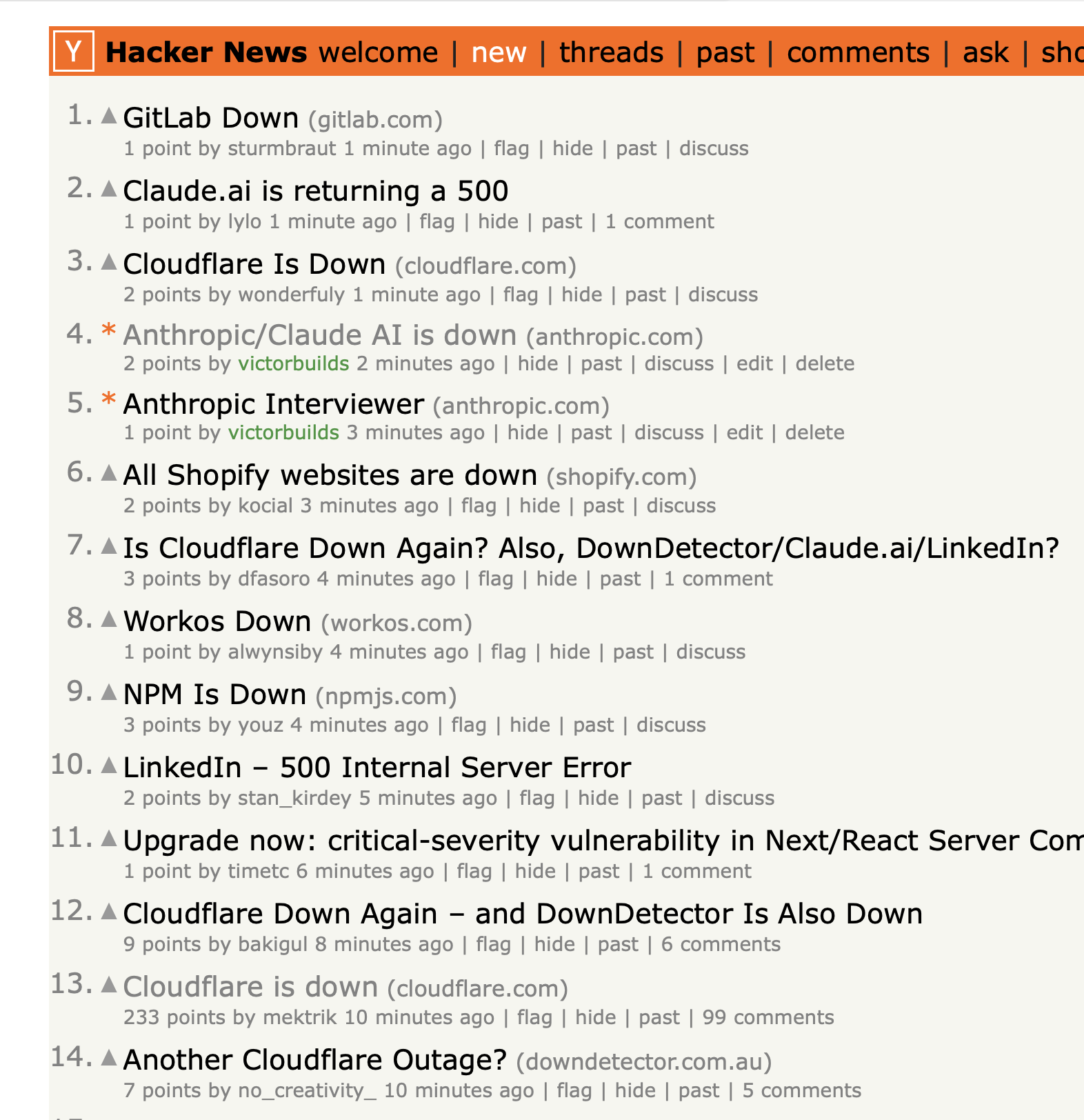
Hacker News turned into a live outage dashboard, with the front page filled entirely with “X is down” posts. It looked less like a tech forum and more like a digital apocalypse feed.
So what’s happening? And why does it feel like half the internet decided to take a synchronized coffee break?
A Perfect Storm of Dependencies
Modern internet architecture is incredibly powerful — but also incredibly interconnected. The services that failed today aren’t random; they’re connected through common infrastructure layers:
1. Cloudflare Outage = Ripple Effects Everywhere
Cloudflare sits in front of huge portions of the internet. When a critical issue hits their network, everything behind them feels the shock: APIs fail, dashboards become unreachable, CDNs time out, frontends collapse.
We’ve seen this pattern before — Cloudflare outages are internet-level events, not isolated incidents.
2. AI Platforms Rely on Shared Compute Providers
Claude.ai returning 500 errors at the same time as Cloudflare issues suggests a possible upstream provider disruption — often these large AI companies share backbone services, GPU infrastructure, or identity/auth systems.
When a foundational service hiccups, all the big players feel it.
3. CI/CD, DevOps, and Package Networks Falling Over
NPM, GitLab, and multiple developer tools also went down. That’s a huge signal: If the tools that build the internet go dark, you know the problem is deeper than a single website glitch.
Why “Multiple Independent Outages” Is Rare
Usually outages happen in isolation — a misconfiguration, a bad deploy, a SQL server that gets a little too excited.
But dozens of global platforms failing within the same 10–15 minute window almost always points to:
- a major network provider disruption
- DNS issues at scale
- CDN routing problems
- BGP announcement mistakes (the internet’s version of “oops, I unplugged the world”)
- large cloud regions experiencing instability
- or, less commonly, a security event unfolding
The recurring theme: infrastructure shared by millions of services is fragile in ways we forget until days like this.
The Illusion of Uptime
We live in a time where everything is expected to be available 24/7 — instant, global, fail-proof. But the more complex the web becomes, the more likely it is that cascading failures will happen.
Today was a reminder that:
- A few companies (Cloudflare, AWS, Azure, Google Cloud) effectively are the internet.
- When they sneeze, the entire web catches a cold.
- No service is truly “independent” anymore.
- And incident dashboards don’t always load when you need them most.
Infrastructure is both incredibly resilient… and incredibly interconnected.
A Strange Silver Lining
There’s something oddly comforting when everything goes down at once. It’s not your computer. Not your browser. Not your Wi-Fi.
It’s just the internet reminding us how ridiculously complex it is.
And if you were wondering: yes, even DownDetector was down.
When the outage detector goes offline, you know things are serious.